Gated recurrent unit
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al.[1] The GRU is like a long short-term memory (LSTM) with a forget gate,[2] but has fewer parameters than LSTM, as it lacks an output gate.[3] GRU's performance on certain tasks of polyphonic music modeling, speech signal modeling and natural language processing was found to be similar to that of LSTM.[4][5] GRUs have been shown to exhibit better performance on certain smaller and less frequent datasets.[6][7]
Architecture
There are several variations on the full gated unit, with gating done using the previous hidden state and the bias in various combinations, and a simplified form called minimal gated unit.[8]
The operator denotes the Hadamard product in the following.

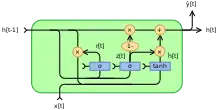
Fully gated unit

Initially, for , the output vector is .



Variables
- : input vector
- : output vector
- : candidate activation vector
- : update gate vector
- : reset gate vector
- , and : parameter matrices and vector








- : The original is a sigmoid function.
- : The original is a hyperbolic tangent.


Alternative activation functions are possible, provided that .



Alternate forms can be created by changing and [9]
- Type 1, each gate depends only on the previous hidden state and the bias.
- Type 2, each gate depends only on the previous hidden state.
- Type 3, each gate is computed using only the bias.



Minimal gated unit
The minimal gated unit is similar to the fully gated unit, except the update and reset gate vector is merged into a forget gate. This also implies that the equation for the output vector must be changed:[10]

Variables
- : input vector
- : output vector
- : candidate activation vector
- : forget vector
- , and : parameter matrices and vector

Content-Adaptive Recurrent Unit

Content Adaptive Recurrent Unit (CARU) is a variant of GRU, introduced in 2020 by Ka-Hou Chan et al.[11] The CARU contain the update gate like GRU, but introduce a content-adaptive gate instead of the reset gate. CARU is design to alleviate the long-term dependence problem of RNN models. It was found to have a slight performance improvement on NLP task and also has fewer parameters than the GRU.[12]
In the following equations, the lowercase variables represent vectors and denote the training parameters, which are linear layers consisting of weights and biases, respectively. Initially, for , CARU directly returns ; Next, for , a complete architecture is given by:




Note that it has at the end of each recurrent loop. The operator denotes the Hadamard product, and denotes the activation function of sigmoid and hyperbolic tangent, respectively.



Variables
- : It first projects the current word into as the input feature. This result would be used in the next hidden state and passed to the proposed content-adaptive gate.
- : Compare to GRU, the reset gate has been taken out. It just combines the parameters related to and to produce a new hidden state .
- : It is the same as the update gate in GRU and is used to the transition of the hidden state.
- : There is a Hadamard operator to combine the update gate with the weight of current feature. This gate had been named as content-adaptive gate, which will influence the amount of gradual transition, rather than diluting the current hidden state.
- : The next hidden state is combined with and .







Data Flow
Another feature of CARU is the weighting of hidden states according to the current word and the introduction of content-adaptive gates, instead of using reset gates to alleviate the dependence on long-term content. There are three trunks of data flow to be processed by CARU:
- content-state: It produces a new hidden state achieved by a linear layer, this part is equivalent to simple RNN networks.
- word-weight: It produces the weight of the current word, it has the capability like a GRU reset gate but is only based on the current word instead of the entire content. More specifically, it can be considered as the tagging task that connects the relation between the weight and parts-of-speech.
- content-weight: It produces the weight of the current content, the form is the same as a GRU update gate but with the purpose to overcome the long-term dependence.

In contrast to GRU, CARU does not intend to process those data flow, instead dispatch the word-weight to the content-adaptive gate and multiplies it with the content-weight. In this way, the content-adaptive gate considers of both the word and the content.
References
- Cho, Kyunghyun; van Merrienboer, Bart; Bahdanau, DZmitry; Bengio, Yoshua (2014). "On the Properties of Neural Machine Translation: Encoder-Decoder Approaches". arXiv:1409.1259.
{{cite journal}}: Cite journal requires|journal=(help) - Felix Gers; Jürgen Schmidhuber; Fred Cummins (1999). "Learning to Forget: Continual Prediction with LSTM". Proc. ICANN'99, IEE, London. 1999: 850–855. doi:10.1049/cp:19991218. ISBN 0-85296-721-7.
- "Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano – WildML". Wildml.com. 2015-10-27. Archived from the original on 2021-11-10. Retrieved May 18, 2016.
- Ravanelli, Mirco; Brakel, Philemon; Omologo, Maurizio; Bengio, Yoshua (2018). "Light Gated Recurrent Units for Speech Recognition". IEEE Transactions on Emerging Topics in Computational Intelligence. 2 (2): 92–102. arXiv:1803.10225. doi:10.1109/TETCI.2017.2762739. S2CID 4402991.
- Su, Yuahang; Kuo, Jay (2019). "On extended long short-term memory and dependent bidirectional recurrent neural network". Neurocomputing. 356: 151–161. arXiv:1803.01686. doi:10.1016/j.neucom.2019.04.044. S2CID 3675055.
- Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun; Bengio, Yoshua (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555 [cs.NE].
- Gruber, N.; Jockisch, A. (2020), "Are GRU cells more specific and LSTM cells more sensitive in motive classification of text?", Frontiers in Artificial Intelligence, 3: 40, doi:10.3389/frai.2020.00040, PMC 7861254, PMID 33733157, S2CID 220252321
- Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun; Bengio, Yoshua (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555 [cs.NE].
- Dey, Rahul; Salem, Fathi M. (2017-01-20). "Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks". arXiv:1701.05923 [cs.NE].
- Heck, Joel; Salem, Fathi M. (2017-01-12). "Simplified Minimal Gated Unit Variations for Recurrent Neural Networks". arXiv:1701.03452 [cs.NE].
- Chan, Ka-Hou; Ke, Wei; Im, Sio-Kei (2020), Yang, Haiqin; Pasupa, Kitsuchart; Leung, Andrew Chi-Sing; Kwok, James T. (eds.), "CARU: A Content-Adaptive Recurrent Unit for the Transition of Hidden State in NLP", Neural Information Processing, Cham: Springer International Publishing, vol. 12532, pp. 693–703, doi:10.1007/978-3-030-63830-6_58, ISBN 978-3-030-63829-0, S2CID 227075832, retrieved 2022-02-18
- Ke, Wei; Chan, Ka-Hou (2021-11-30). "A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis". Applied Sciences. 11 (23): 11344. doi:10.3390/app112311344. ISSN 2076-3417.